Just in time for the upcoming break, we have figured out how to do alpha-test, and now supertuxkart is rendering properly:
If you are wondering about the new stk beta, I have a build from a few weeks back which seems to render properly as well.. few rough edges but I think that is just from using random git commit-id for stk. But we don't have enough gl3 features yet (on a3xx or a4xx) to be using the new rendering paths.
And gnome-shell works nicely too. Still some rendering issues with xonotic. And a little ways behind a3xx in piglit results, but not quite as much as I would have expected at this early stage. Still missing are some optimizations that are important for certain use-cases (hw-binning support for games, GMEM bypass for UI/mipmap-generation/etc). But the a420 in apq8084 (ifc6540 board) is surprisingly fast all the same.
A couple weeks ago, qualcomm (quic) surprised some by sending kernel patches to enable the new adreno 4xx family of GPUs found in their latest SoCs. Such as the apq8084 powering my ifc6540 board with the a420 GPU. Note that qualcomm had already sent patches to enable display support for apq8084, merged in 3.17. And I'm looking forward to more good things from their upstream efforts in the future. So in the last weeks, in between various other kernel work (atomic-helper conversion and few other misc things for 3.19) and RHEL stuff, I've managed to bang out initial gallium support for a4xx. There are still plenty of missing things, or stuff hard-coded, etc. But yesterday I managed to get textures working, and fix RGBA/BGRA confusion, so now enough works for 'gears and maybe about half of glmark2:
I've intentionally pushed it (just now) after the mesa 10.4 branch point, since it isn't quite ready to be enabled by default in distro mesa builds. When it gets to the point of at least being able to run a desktop environment (gnome-shell / compiz / etc), I may backport to 10.4. But there is still a lot of work to do. The good news is that so far it seems quite fast (and that is without hw binning or XA yet even!)
In the process of reverse engineering work for freedreno, I've cobbled together some interesting tools. The earliest and most useful of which is cffdump. (Named after some command-stream dumping debug code in the old kgsl android kernel driver, upon which it was originally inspired.) The cffdump tool knows how to parse out the "toplevel" command-stream stored as an .rd (re-dump) file, finding packets that load state memory, write registers, IB (indirect branch), etc. The .rd file contains snapshots of gpu buffers, in order to chase gpu pointers at decode time. It links in librnn from the nouveau envytools project for the decoding of individual registers, and a few other things. It also calls out to the freedreno disassembler code to show inline disassembly of shaders, decodes vertex and constant (uniform) buffers, etc. And even generates pretty color output (thanks to librnn):
A few months back, I added some basic lua scripting support to cffdump, mostly to assist in r/e work for adreno a4xx. When invoked with the --script argument, cffdump would load the specific lua script, and call the 'draw' function it defines on each CP_DRAW_INDX opcode. The choice of lua was mostly because it seemed fairly easy to integrate with .c code. Since then, I've had the thought in the back of my mind that adding script bindings to integrate rnn register decode to lua would be useful for much more. Such as writing a command-stream validator to check for inconsistent programming. There are a number of places where inconsistencies between various register settings and such will result in gpu lockup. The general adreno design philosophy appears to be to not ever dedicate transistors to making the driver writer's life easier... which for a SoC gpu is certainly the right choice, but it doesn't make things any easier for me. Over time, I've discovered many of these of these rules, but they are mostly all in my head at the moment. And from time to time, when adding new features to the gallium driver, I inadvertently break one or more of the rules and end up wasting time studying cmdstream dumps from the freedreno gallium driver to figure out what I did wrong.
So, on the way to XDC2014 I started hacking up support for register decoding from lua scripts. It turns out that time in airports and airplanes, where I can't exactly break out an ifc6410 and hdmi monitor to do some driver work, is a good time to catch up on these sort of projects. Now I can do nifty things like:
-- load rnn database file for a320: r = rnn.init("a320") function start_cmdstream(name) io.write("START: " .. name .. "\n") end function draw(primtype, nindx) -- simple full register access: io.write("GRAS_CL_VPORT_XOFFSET: " .. r.GRAS_CL_VPORT_XOFFSET .. "\n") -- access boolean bitfield Z_ENABLE in RB_DEPTH_CONTROL register: io.write("RB_DEPTH_CONTROL.Z_ENABLE: " .. tostring(r.RB_DEPTH_CONTROL.Z_ENABLE) .. "\n") -- access ROP_CONTROL bitfield inside CONTROL register inside RB_MRT[] array: io.write("RB_MRT[0].CONTROL.ROP_CODE: " .. r.RB_MRT[0].CONTROL.ROP_CODE .. "\n") end function end_cmdstream() io.write("END\n") end function finish() io.write("FINISH\n") end
Currently it should handle all of the rnndb constructs that are used for adreno. Ie. simple registers, arrays of simple registers, arrays of groups of registers, etc. No support for "stripes" yet since those are not used for freedreno. At the moment, all the script bindings are in freedreno.git/util/script.c but if there is some interest in this from nouveau or anyone else using librnn then it would be a good idea to try to refactor some of this into more generic code in librnn. It would still need a bit of glue from the tool linking librnn to get at the actual register values.
Still needed are a few more script hooks (such as CP_LOAD_STATE) to do everything I need for a validator script. Hopefully I find some time to work on that before the next conference ;-)
PS. I hope this post is at least a bit coherent.. I am still a bit jetlagged..
A number of people have recently asked what is new with freedreno. It had been a while since posting an update.. and, well, not everyone watches mesa commit logs for fun, or watches #freedreno on freenode, so it seemed like time for another semi-irregular freedreno blog post. The tl;dr version: recently it has been a lot of robustness, and bug fixes and smaller feature implementation for piglit, etc. No one big exciting feature this time.. but lots of little things adding up to make freedreno on a3xx more complete and mature.
And an obligatory screenshot, just because:
(Yeah, webgl should probably be faster in chrome/chromium.. but not packaged for fedora, and chrome build system was invented by someone who wants to make compiling their src as difficult as possible.)
Mesa.. On the mesa/gallium driver front, the big news is that earlier this week we finally achieved a 90% pass ratio for piglit. (In fact, 90.4%) To put this in perspective, a little over six months ago freedreno was at just 50% pass. Since June, we have added around 600 passing tests. In fact in the last week, an additional ~50 tests are passing, which bumps us up to 91% pass. For those who are not familiar with it, piglit is an open source OpenGL test suite. Since the mesa developers are quite good about adding new test cases to piglit whenever adding a new feature/extension to mesa, it is a very comprehensive test suite. The down side, if you could call it that, is that it has a lot more OpenGL tests compared to OpenGLES (at least for GLES < 3.0). So getting the pass ratio up involved implementing (and in some cases emulating) a number of features that the blob ES-only driver does not support. Fortunately enough of the registers and bitfields are known at this point that trial and error with educated guesses (and then see which guesses make piglit tests pass) has worked out reasonably well for some features. Other features, like GL_CLAMP and two sided color, we need to emulate in the shader, which was implemented as a TGSI to TGSI pass in order to hopefully be useful for other gallium drivers for GLES class hardware. (And, in fact both of those are things that at least some of the desktop drivers need to emulate as well.) And big thanks to Ilia Mirkin for a lot of advice and some patches for the failing piglits. Ilia has also started sending a lot of patches for the compiler to flesh out integer support, add new instructions (in particular texture sample instructions), and other things that will be needed for GL3/GLES3. In fact as a result of his work, we are already at ~85% pass for GL3 despite missing some bullet-point features! DDX.. On the xf86-video-freedreno front, over the last few months we have gained server managed fd's and OutputClass support (so that a sufficiently new xserver can auto-pick the correct driver, like we have had for a long time on desktop/pci systems). And a hot-off-the-presses 1.3.0 release with a handful of robustness fixes. I strongly recommend to upgrade. Kernel.. These last few kernel releases have seen a significant improvement in the state of apq8064/ifc6410 support upstream. As of the 3.17 kernel, the main things missing to work on a pure-upstream[1] kernel are the rpm/rpm-regulators iommu drivers. The linaro folks have been a big help there. In particular, their integration branch, which consists of latest upstream plus in-flight patches, is significantly easier than tracking all the relevant kernel mailing lists.
For drm/msm, the last few kernel releases have seen: some basic gpu perf and logging debugfs features, DT support for mdp4 (display controller version in apq8064), LVDS and multi-monitor support for mdp4, and mdp5 v1.3 support from qcom for upcoming devices. And of course bug fixes!
[1] Ie. Linus's tree... kernel-msm or AOSP is not upstream, for any android type's who were confused about that.
This will, I
think, be the first time blogging about something quite so
retroactively, but for reasons which should be apparent, I could not blog about this little adventure until now. This is the story
of CVE-2014-0972 (QCIR-2014-00004-1), and (at least part of) how I was able to install fedora on my firetv:
Introduction..
Back in April, I bought myself a Fire TV, with the thought that it would make a nice fedora xbmc htpc setup, complete with open src drivers, to replace my aging pandaboard. But, of course, as delivered the Fire TV is locked down with no root access.
At the same time, there was a feature of the downstream android kernel gpu driver (kgsl), per-context pagetables, which had been on my TODO list for the upstream drm/msm driver for a while now. But, I needed to understand better what kgsl was doing and the interactions with the hardware, in particular the behaviour of the CP (command processor), in order to convince myself that such a feature was safe. People generally frown on introducing root holes in the upstream kernel, and I didn't exactly have documentation about the hardware. So it was time to roll up my sleeves and get some hands-on experience (translation: try to poke and crash the gpu in lots of different ways and try to make sense of the result).
Into the rabbit hole..
The modern snapdragon SoCs use IOMMUs everywhere. Including the GPU. To implement per-context gpu pagetables, basically all the driver needs to do is to bang a few IOMMU registers to change the pagetable base addr and invalidate the TLB. But this must be done when you are sure the GPU is not still trying to access memory mapped in the old page tables. Since a GPU is a highly asynchronous device, it would be a big performance hit to stall until GPU ringbuffer drains, then reprogram IOMMU, then resume the GPU with commands from the new context. To avoid this performance hit, kgsl maps some of the IOMMU registers into the GPU's virtual address space, and emits commands into the ringbuffer for the CP to write the necessary registers to switch pagetables and invalidate TLB.
It was this reprogramming of IOMMU from the GPU itself which I needed to understand better. Anyone who understands GPU's would have the initial reaction that this is extremely dangerous. But kgsl was, it seemed, taking some protections. However, I needed to be sure I properly understood how this worked, to see if there was something that was overlooked.
The GPU, in fact, has two hw contexts which it can switch between. Essentially it is in some ways similar to supervisor vs user context on a CPU. The way kgsl uses this is to map the IOMMU registers into the supervisor context, but not user contexts. The ringbuffer is mapped into all the user contexts, plus supervisor context, at the same device virtual address. The idea being that if the ringbuffer is mapped in the same position in all contexts, you can safely context switch from commands in the ringbuffer.
To do this, kgsl emits commands for the CP to write a special bit in CP_STATE_DEBUG_INDEX to switch to the "supervisor" context. Then commands to write IOMMU registers, followed by write to CP_STATE_DEBUG_INDEX to switch back to user context. (I'm over-simplifying slightly, as there are some barriers needed to account for asynchronous writes.) But userspace constructed commands never execute from the ringbuffer, instead the kernel puts an IB (indirect branch) into the ringbuffer to jump to the userspace constructed cmdstream buffer. This userspace cmdstream buffer is never mapped into supervisor context, or into other user's contexts. So in theory, if userspace tried to write CP_STATE_DEBUG_INDEX to switch to supervisor mode (and gain access to the IOMMU registers), the GPU would immediately page fault, since the cmdstream it was in the middle of executing is no longer mapped. Ok, so far, so good.
Where it breaks down..
From my attempts at switching to supervisor mode from IB1, and deciphering the fault address where the gpu crashed, and iommu register dumps, I could tell that the next few commands after the switch to supervisor mode where excuted without problem.. there is some prefetch/pipelining!
But much more conveniently, while poking around, I realized that there were a couple pages mapped globally (in supervisor and all user contexts), which where mapped writable in user contexts. I used the so called "setstate" buffer. So I simply had to construct a cmdstream buffer to write the commands I wanted to execute into the setstate buffer, and then do an IB to that buffer and do the supervisor switch in IB2.
Ok.. but do do anything useful with this, I'd need a reasonable chunk of physically contiguous pages, at a known physical address.. in particular 16K for first level pagetables and 16K second level pagetables. Fortunately ION comes to the rescue here, with it's physically contiguous carveouts at known physical addresses. In this case, allocate from the multimedia pool when there is no video playback, etc, going on. This way ION allocates from the beginning of the carveout pool, a known address.
Into this buffer, construct a new set of pagetables, which map whatever physical address you want to read/write (hint, any of kernel lowmem), a replacement page for the setstate buffer (since we don't know the original setstate buffer's physical address.. which means we actually have two copies of the commands copied into setstate buffer, one copied via gpu to original setstate page, and one written directly by cpu in the replacement setstate page).
The proof of concept that I made simply copied the string "Kilroy was here" into a kernel buffer. But quite easily any random app downloaded from an untrusted source could access any memory, become root, etc. Not the sort of thing you want falling into the wrong hands.
Once I managed to prove to myself that I understood properly how the hw was working, I wrote up a short report, and submitted it (plus proof of concept) to the qualcomm security team.
Now that the vulnerability is no longer embargoed, I've made available the proof of concept and report here. Originally I planned to (once fixes were pushed out, so as to not put someone who did not intend to root their device at risk) release a jailbreak based on this vulnerability. But once towelroot was released, there was no longer a need for me to turn this into an actual firetv jailbreak. Which saves me from having to figure out how to make an apk.
Parting thoughts..
Well, knownledge about physical addresses and contiguous memory in userspace, while it might not be a security problem in and of itself, it sure helps turn other theoritical exploits into actual exploits.
As far as downstream vendor drivers go, the kgsl driver is actually pretty decent, in terms of code quality, etc. I've seen far worse. Admittedly this was not a trivial hole. But imagine what issues lurk in other downstream gpu/camera/video/etc drivers. Security is often not simple, and I really doubt whether the other downstream drivers are getting a critical look (from good-guys who will report the issue responsibly).
I used to think of the whole one-kernel-branch-per-device wild-west ways of android as a bit of a headache. Now I realize it is a security nightmare. An important part of platform security is being able to react quickly when (not if) vulnaribilites are found. In the desktop/server world, CVEs are usually not embargoed for more than a week.. that is all you need, since fortunately we don't need a different kernel for each different make and model of server, laptop, etc. In the mobile device world, it is quite a different story!
I've just pushed to upstream mesa support for occlusion query, which means that freedreno now advertises OpenGL 2.0:
OpenGL vendor string: freedreno OpenGL renderer string: Gallium 0.4 on FD320 OpenGL version string: 2.0 Mesa 10.3.0-devel (git-00fcf8b) OpenGL shading language version string: 1.20
Note that this is desktop OpenGL. Freedreno has supported OpenGLES 2.0 for quite a long time now. Implementing occlusion query was a bit interesting due to the way the tiling works on adreno. We have to track query results per tile. I've written up a bit of a description about how it works on the wiki: Hardware Queries
Looks like next up is sRGB support which gets us up to GL 2.1. And then the fun begins with work on GL/GLES 3.0 :-)
EDIT: turns out sRGB texture support is pretty easy. So now we are GL 2.1. (GL/GLES 3.0 also needs sRGB render target support which is a bit more involved. But there that is just one of several features needed for 3.0).
Complementing the hw binning support which landed earlier this year, and is now enabled by default, I've recently pushed the initial round of new-compiler work to mesa. Initially I was going to keep it on a branch until I had a chance to sort out a better register allocation (RA) algorithm, but the improved instruction scheduling fixed so many bugs that I decided it should be merged in it's current form.
Or explained another way, ever since fedora updated to supertuxkart 0.8.1, about half the tracks had rendering problems and/or triggered gpu hangs. The new compiler fixed all those problems (and more). And I like supertuxkart :-) Background: The original a3xx compiler was more of a simple TGSI translator. It translated each TGSI opcode into a simple sequence of one or more native instructions. There was a fixed (per-shader) mapping between TGSI INPUT, OUTPUT, and TEMP vec4 register files to the native (flat) scalar register file. A not-insignificant part of the code was relatively generic, in concept but not implementation, lowering of TGSI opcodes that relate more closely to old ARB shader instructions, (SCS - Sine Cosine, LIT - Light Coefficients, etc) than the instruction set of any modern GPU. The simple TGSI translator approach works fine with simple shader ISA's. It worked ok for a2xx, other than slightly suboptimal register usage. But the problem is that a3xx (and a4xx) is not such a simple instruction set architecture. In particular, the instruction scheduling required that the compiler be aware of the shader instruction pipeline(s). This was obvious pretty early on in the reverse engineering stage. But in the early days of the gallium a3xx support, there were too many other things to do... spending the needed time on the compiler then was not really an option. Instead the "use lots of nop's and hope for the best" strategy was employed. And while it worked as a stop-gap solution, it turns out that there are a lot of edge cases where "hope for the best" does not really work out that well in practice. After debugging a number of rendering bugs and piglit failures which all traced back to instruction scheduling problems, it was becoming clear that it was time for a more permanent solution.
In with the new:
First thing I wanted to do before adding a lot more complexity is to rip out a bunch of code. With that in mind I implemented a generic TGSI lowering pass, to replace about a dozen opcodes with sequences of equivalent simpler instructions. This probably should be made configurable and moved to util, I think most of the lowerings would be useful to other gallium drivers. Once the handling of the now unneeded TGSI opcodes was removed, I copied fd3_compiler to fd3_compiler_old. Originally the plan was to remove this before pushing upstream. I just wanted a way to compare the results from the original compiler to the new compiler to help during testing and debugging. But currently shaders with relative addressing need to fall back to the old compiler, so it stays for now. The next step was to turn ir3 (the a3xx IR), which originates from the fdre-a3xx shader assembler into something more useful. The approach I settled on (mostly to ease the transition) was to add a few extra "meta-instructions" to hold some additional information which would be needed in later passes, including Φ (Phi) instructions where a result depends on flow control. Plus a few extra instruction and register flags, the important one being IR3_REG_SSA, used for src register nodes to indicate that the register node points to the dependent instruction. Now what used to be the compiler (well, roughly 2/3rds of it) is the front-end. Instead of producing a linear sequence of instructions fed directly to the assembler/codegen, the frontend is now generating a graph of instructions modified by subsequent passes until we have something suitable for codegen.
For each output, we keep the pointer to the instruction which generates that value (at the scalar level), which in turn has the pointer to the instructions generating it's srcs/inputs, and so on. As before, the front end is generating sequences of scalar instructions for each (written) component in a TGSI vector instruction. Although now instructions whose result is not used simply has nobody pointing to them so they naturally vanish. At the same time, mostly to preserve my sanity while debugging, but partially also to make nifty pictures, I implemented an "ir3 dumper" which would dump out the graph in .dot syntax:
The first pass eliminates some redundant moves (some of which come from the front end, some from TGSI itself). Probably the front end could be a bit more clever about not inserting unneeded moves, but since TGSI has separate INPUT/OUTPUT/TEMP register files, there will always be some extra moves which need eliminating.
After that, I calculate a "depth" for each instruction, where the depth is the number of instruction cycles/slots required to compute that value: dd(instr, n): depth(instr->src[n]) + delay(instr->src[n], instr) depth(instr): 1 + max(dd(instr, 0), ..., dd(instr, N)) where delay(p,c) gives the required number of instruction slots between an instruction which produces a value and an instruction which consumes a value. The depth is used for scheduling. The short version of how it works is to recursively schedule output instructions with the greatest depth until no more instructions can be scheduled (more delay slots needed). For instructions with multiple inputs/srcs, the unscheduled src instruction with the greatest depth is scheduled first. Once we hit a point where there are some delay slots to fill, we switch to the next deepest output, and so on until the needed delay slots are filled. If there are no instructions that can be scheduled, then we insert nop's. Once the graph is scheduled, we have a linear sequence of instructions, at which point we do RA. I won't say too much about that now, since it is already a long post and I'll probably change the algorithm. It is worth noting that some register assignment algorithms can coalesce unneeded moves. Although moves factor into the scheduling decisions for the a3xx ISA, so I'm not really sure that this is too useful me.
The end result, thanks to a combination of removal of scalar instructions to calculate TGSI vec4 register components which are unused, plus removal of unnecessary moves, plus scheduling other instructions rather than filling with no-op's everywhere, for non trivial shaders it is not uncommon to see the compiler use ~33% the number of instructions, and half the number of registers. Testing/Debugging:
Validating compilers is hard. Piglit has a number of tests to exercise relatively specific features. But with games, it isn't always the case that an incorrect shader produces (visually) incorrect results. And visually incorrect results are not always straightforward to trace back to the problem. Ie. games typically have many shaders, many draw calls, tracking down the problematic draw and it's shaders is not always easy. So I wrote a very simplistic emulator for testing the output of the compiler. I captured the TGSI dumps of all the shaders from various apps (ST_DEBUG=tgsi). The test app would assemble the TGSI, feed into both the old and new compiler, then run same sets of randomized inputs through the resulting shaders and compare outputs.
There are a few cases where differing output is expected, since the new compiler has slightly more well defined undefined behaviour for shaders that use uninitialized values... to avoid invalid pointers in the graph produced by the front-end, uninitialized values get a 'mov Rdst, immed{0.0}' instruction. So there are some cases where the resulting shader needs to be manually validated. But in general this let me test (and debug) the new compiler with 100's of shaders in a relatively short amount of time. Performance:
So the obvious question, what does this all mean in terms of performance? Well, start with the easy results, es2gears[1]:
original compiler: ~435fps
new compiler: ~539fps
With supertuxkart, the result is a bit easier to show in pictures. Part of the problem is that the tracks that are heavy enough on the GPU to not be purely CPU limited, didn't actually work before with the original compiler. That plus, as far as I know, there is no simple benchmark mode which spits out a number at the end, as with xonotic. So I used the trace points + timechart approach, mentioned in a previous post. supertuxkart -f --track fortmagma --profile-laps=1 I manually took one second long captures, in as close to the same spot as possible (just after light turns green): ./perf timechart record -a -g -o stk-apq8074-opt+bin-1.data sleep 1 In this case I was running on an apq8074/a330 device, fwiw. Our starting point is:
Then once hw binning is in place, we are starting to look more CPU limited than anything:
And with addition of new compiler, the GPU is idle more of the time, but since the GPU is no longer the bottleneck (on the less demanding tracks) there isn't too much change in framerate:
Still, it could help power if the GPU can shut off sooner, and other levels which push the GPU harder benefit. With binning plus improved compiler, there should not be any more huge performance gaps compared to the blob compiler. Without linux blob drivers, there is no way to make a real apples to apples comparison, but remaining things that could be improved should be a few percent here and there. Which is a good thing. There are still plenty of missing features and undiscovered bugs, I'm sure. But I'm hopefully that we can at least have things in good shape for a3xx before the first a4xx devices ship ;-)
-----
[1] Windowed apps
would benefit somewhat from XA support in DDX, avoiding stall for GPU to
complete before sw blit (memcpy) to front buffer.. but the small
default window size for 'gears means that hw binning does not have much
impact. The remaining figures are for fullscreen 1280x720.
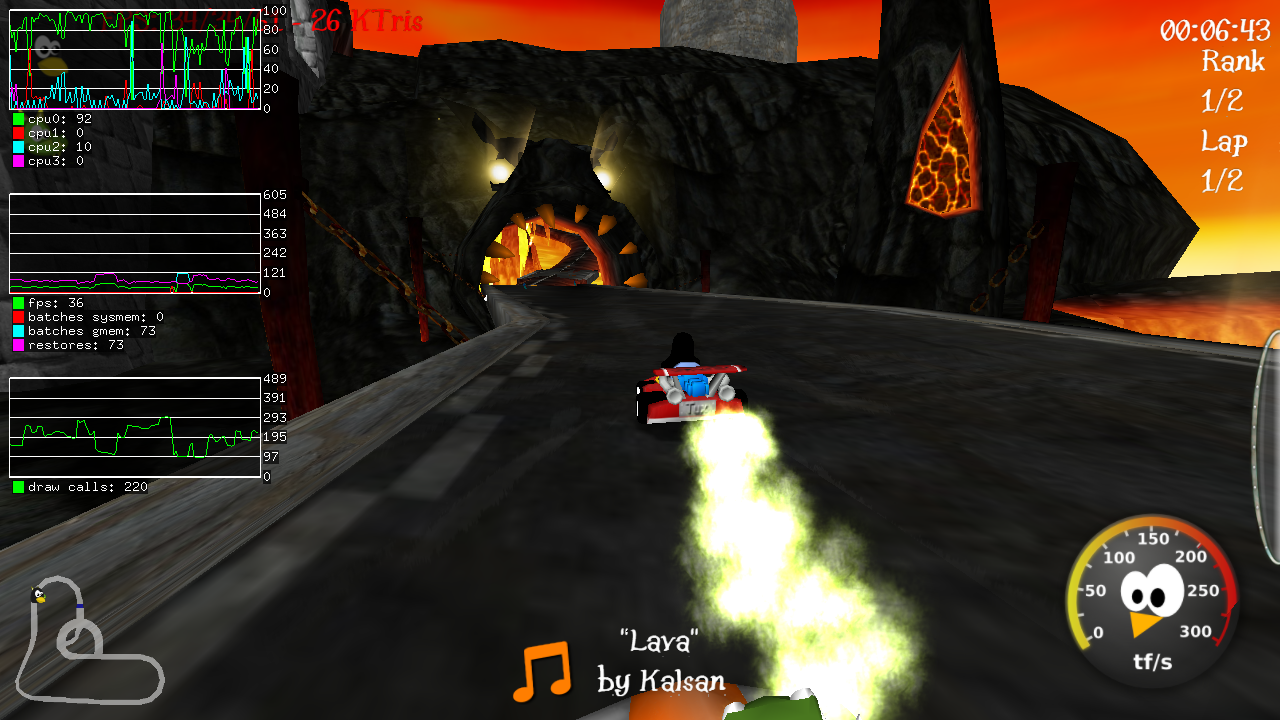
Time for another freedreno update. hw binning support, and fun with gallium HUD. Mesa/Gallium: The big news is that hw binning pass support (for a3xx) is working. This is a pre-pass for all the draws which generates a visibility stream (ie. basically which vertices apply to which tiles) used to speed up the tile rendering step by filtering out non visible vertices for a given tile. tl;dr: games or anything with a healthy vertex loading (ie. not window managers) are showing 35-45% fps boost. Currently it is not enabled by default. I'd like some time for it to get more testing before it is enabled by default. For now, use the FD_MESA_DEBUG environment variable to enable it, ie: FD_MESA_DEBUG=binning supertuxkart Also, since I was looking for a way to correlate fps with various other statistics (in particular batches per second vs frames per second), I started playing with the gallium performance monitor HUD (heads-up-display). With the addition of a few driver custom queries, I had what I needed:
The driver custom queries:
draw-calls
batches - number of batches per second, sum of batches-sysmem plus batches-gmem
batches-gmem - a set of tiles in GMEM rendered, for each tile (optionally) system mem -> gmem (restore), plus N draws, plus gmem -> system mem (resolve); value in batches per second
batches-sysmem - draws to system memory (GMEM bypass) per second
restores - number of GMEM batches that required restore per second
So above screenshot was generated with: export GALLIUM_HUD=cpu0+cpu1+cpu2+cpu3,fps+batches-sysmem+batches-gmem+restores,draw-calls export FD_MESA_DEBUG=binning supertuxkart -s 1280x720 --demo-mode 1 The binning and query support are on mesa master.